:quality(80)/p7i.vogel.de/wcms/b5/ae/b5ae6808f29fc09bf61b47807604bcf4/0131740517v2.jpeg "Wenn KI Aktuatoren steuert, wird Edge AI zur Physical AI. Hinsichtlich der Software-Entwicklung kommt es dabei nicht nur auf die Modelleistung an: gerade Safety, Compliance und eine zertifizierte Toolchain werden hier zu entscheidenden Faktoren. (Bild: @homaappliances/Unsplash)")
:quality(80)/p7i.vogel.de/wcms/b8/20/b8203d9f2b6f6e61bff6c3fda15042d3/0128235802v2.jpeg "Die Forschenden aus dem Lehrstuhl für Robotik, Künstliche Intelligenz und Echtzeitsysteme testen die neue Architektur am Teststand der TUM. Im Bild (von links nach rechts): Chengdong Wu, Nils Purschke und Sven Kirchner. (Bild: besser 3 / TU München)")
:quality(80)/p7i.vogel.de/wcms/79/90/79901d8c1934b11223a53cb900b1aa85/das-20building-2092-20bei-20der-20microsoft-zentrale-20in-20redmond-20--20quelle-20coolcaesar-20via-20wikimedia-20commons-5184x2915v1.jpeg "Das Building 92 bei der Microsoft-Zentrale in Redmond. (Wikimedia Commons)")
:quality(80)/p7i.vogel.de/wcms/31/92/3192d2bddbdb052afd8904128dd7aec1/0123884994v2.jpeg "Projekte zur Entwicklung von Embedded-Systemen, wie auch die Systeme selbst, werden zunehmend komplexer. Modellbasiertes System-Engineering (MBSE) soll dabei helfen, diese zunehmende Komplexität in den Griff zu bekommen. Doch wann stößt das Prinzip an seine Grenzen? (Bild: KI-generiert / DALL-E)")
:quality(80)/p7i.vogel.de/wcms/da/34/da343cfac1c945d425a8c650abd7c448/0131414071v2.jpeg "Softwaredefinierte Systeme müssen auch dann zuverlässig zusammenarbeiten, wenn Netzwerke schwanken oder ausfallen. RTI Connext und der Persistence Service können dafür sorgen, konsistente Datenflüsse zu gewährleisten. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/ba/d7/bad734452b1b8360591396b49da37b72/0130644400v1.jpeg "Die Begriffe Echtzeit und Virtualisierung erscheinen zunächst widersprüchlich, da sie auch aus den konträren Domänen OT (Operational Technology) und IT (Information Technology) stammen. Virtualisierung bedeutet aber im Wesentlichen die Entkopplung einer bestimmten Applikation von der zugrunde liegenden Hardware, was keinen direkten Kontrast zu Echtzeit bedeuten muss. Dieser Artikel erläutert die verschiedenen technischen Möglichkeiten, eine Applikation von der Hardware zu entkoppeln, um anschließend deren individuelle Tauglichkeit zum Ablauf echtzeitkritischer Systeme zu evaluieren. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/cc/53/cc53ebfd9f45b28eb918a8098b63846b/0127825678v1.jpeg "Im zweiten und letzten Teil der Artikelserie zu Latenzen wird gezeigt, wie sich Latenz mit dem richtigen RTOS, Interrupt-Optimierung, Low-Level-Code und Co-Design gezielt senken lässt. (Bild: Green Hills Software)")
:quality(80)/p7i.vogel.de/wcms/ac/ea/acea3ca6c15e0bd261c8bde5d3fe7bfb/0127825678v2.jpeg "Bild 1: Um Latenzzeiten in echtzeitkritischen Systemen verringern zu können braucht es erst einmal Verständnis, wie diese entstehen. Im ersten Teil unserer zweiteiligen Reihe werden die Schlüsselfaktoren untersucht, die sowohl auf Hardware- als auch auf Software-Ebene zur Latenz beitragen. (Bild: Green Hills Software)")
:quality(80)/p7i.vogel.de/wcms/56/9b/569b4da4d1f2e4ce6f41918f86d00c04/0131738385v2.jpeg "Laut der Atlassian-Studie „State of Teams 2026“ verlieren Fortune-500-Unternehmen jedes Jahr schätzungsweise 161 Milliarden US-Dollar durch KI-bedingte Reibungsverluste. Das Problem ist mangelnde Koordination: 80 Prozent der Arbeit in Unternehmen findet innerhalb von Teams oder teamübergreifend statt, aber nur 24 Prozent der Führungskräfte legen ihre KI-Initiativen gezielt auf diese Zusammenarbeit aus. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/d9/c1/d9c121f0680f16e547502038f5c26481/0130027942v2.jpeg "Laut dem aktuellen State of Automotive Software Development Report von Perforce verwenden bereits 71 % der befragten Unternehmen KI in der Entwicklung von Fahrzeugsoftware. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/75/3d/753d0fa44b344d363e25c91dc0752635/0129134302v2.jpeg "Volle Säle, reger Austausch: Trotz einer spürbaren Konjunkturflaute gerade im Automotive-Bereich fanden sich erneut um die 1000 Teilnehmer in der Stadthalle Sindelfingen zum ESE Kongress 2025 ein. (Bild: Nicolas Det)")
:quality(80)/p7i.vogel.de/wcms/29/df/29dfe92c81f1d3608224694316b2179b/0131967433v1.jpeg "„Patch the Planet“: Die von OpenAI gestartete Initiative soll mittels KI-gestützter Sicherheitsanalyse Open-Source-Maintainer entlasten, indem potenzielle Schwachstellen vor der Weitergabe an Projekte von Experten geprüft und in belastbare Patches überführt werden. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/e3/f3/e3f3e7bf05f03eb91d7c4d3d0c388b96/0131831391v2.jpeg "Während Desktop-Systeme heute standardmäßig mit Exploit-Mitigation-Mechanismen abgesichert sind, fehlen vergleichbare Schutzmaßnahmen in vielen Embedded Devices noch immer. Das macht vernetzte Geräte im Feld zu einem attraktiven Angriffsziel und verschärft den Handlungsdruck für Hersteller. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/0d/9b/0d9be5033416dffb1b4f5cc050560a25/0131796023v2.jpeg "Vom Gateway zur Central Unit: Im SDV werden Fahrzeugfunktionen zentralisiert und müssen über klare Partitionierung, Isolation und Safety-Scope abgesichert werden. (Bild: Elektrobit)")
:quality(80)/p7i.vogel.de/wcms/8b/a7/8ba78f02e76e08a21fe98487faa35225/0131725834v1.jpeg "Die Neugründung eines KI-Sicherheitsinstituts soll insbesondere auf die digitale Souveränität Deutschlands einzahlen. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/41/c9/41c91ed48343a6014ddcd2aaa9029248/0130954766v2.jpeg "In welcher Programmiersprache wird Fahrzeug-Software geschrieben? Diese Frage rückt nunmehr in Bereiche, in denen über Architektur, Risiko und Zulassung entschieden wird. (Bild: frei lizensiert bei Pexels)")
:quality(80)/p7i.vogel.de/wcms/38/41/384121ebf647b1fc2149044fe5857c51/0131567723v2.jpeg "Microsoft plant, bis zum Release von C# 16 die Speichersicherheit der Programmiersprache grundlegend zu verbessert. Dabei orientiert sich das Entwicklerteam an Paradigmen, die aus Rust bekannt sind. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/47/f5/47f5a305c48bfcaf3daae7e6b7478a0f/0131065910v2.jpeg "Rust hält Einzug in die Fahrzeugsoftware und adressiert vor allem Speicher- und Sicherheitsrisiken in vernetzten Steuergeräten. Für OEMs und Zulieferer stellt sich damit weniger die Frage „Rust oder C“, sondern welche Komponenten zuerst von einem Wechsel profitieren. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/23/23/2323167fce16d7a31011ac17a97933c9/0129855253v2.jpeg "C ist als Programmiersprachen seit Jahrzehnten etabliert, doch bestimmte Anfängerfehler finden sich immer wieder. Vom Vergessen des NULL-Terminators bis zum Abgleich von C-Strings: Dies sind die häufigsten Fehltritte von C-Einsteigern. (Bild: IAR Systems)")
:quality(80)/p7i.vogel.de/wcms/36/14/36149e1b05c9f269b5ea6cdb4bd732e6/0131957621v2.jpeg "Im Vergleich zum April-Release weist das jüngste Wartungs-Update von Rasperry Pi OS nur einoge Ergänzungen und Fehlerkorrekturen auf. Am Bedeutendsten sind der Umstieg auf den Linux-LTS-Kernel 6.18.3 sowie einer bessere, einheitlichere Unterstürtzung für Touchscreens. (Bild: Raspberry PI)")
:quality(80)/p7i.vogel.de/wcms/2e/89/2e8965af7611ed0c0db93bdb9f973cbb/0131759111v1.jpeg "Fractal basiert auf einem neuen Konzept: dem „Outer Kernel“-Thread, der sich im Speicher eines Benutzerprozesses befindet, aber mit Kernel-Rechten ausgeführt wird. Entwicklerund MIT-Doktorand Joseph Ravichandran bezeichnet das resultierende Betriebssystem als das „Elektronenmikroskop der Betriebssysteme“. (Bild: MIT / Gabriel Maragaño)")
:quality(80)/p7i.vogel.de/wcms/bd/15/bd15e3adf9e8d2e15c1485d809078729/0131621839v2.jpeg "Sicherheitsforscher melden manipulierte Red-Hat-Pakete im npm-Registry. Betroffene Systeme, welche die befallenen Pakete heruntergeladen haben, gelten als direkt kompromittiert, weil der Schadcode schon bei der Installation ausgeführt wird. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d8/b1/d8b155da6f9b74886c34845a83ce451d/0131897755v1.jpeg "Das Marketingversprechen verspricht eine reibungslose Code-Übersetzung. In der Praxis bricht die automatisierte Migration komplexer Legacy-Systeme laut Gartner an ihren eigenen Grenzen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d2/e9/d2e9736dbd5b904cb34192c7b350e1d5/0131669814v2.jpeg "Unter dem Druck des Managements wiegt die schnelle Veröffentlichung von Software oft mehr als ihre Qualität. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/8a/09/8a094e681c2f4b9aefbeb7bd2732af4a/0131173224v1.jpeg "Unit-Tests in regulierten Branchen müssen mehr leisten als reine Fehlerprüfung. Der Artikel zeigt, wie GoogleTest bewertet wird und welche Rolle C/C++test CT dabei spielen kann. (Bild: Parasoft)")
:quality(80)/p7i.vogel.de/wcms/2e/b2/2eb2a82d215c72f59c1fde532c092e87/0131010297v2.jpeg "MRT-Bilderkennungssystem: Gerade in der Medizintechnikkann der Einsatz von KI in einem Embedded Sytsem massive Vorzüge Bbringen. Umso mehr kommt es dabei aber auch auf die Zuverlässigkeit der Tests an, um Safety-Standards einzuhalten. (Bild: Magnific / Yaroslav Astakhov)")
:quality(80)/p7i.vogel.de/wcms/ea/0e/ea0efaeee8bfe8fe9b2b7b9153ba55d8/0131965389v2.jpeg "Laut einer Bitkom-Studie lässt die Zunahme von KI-gestützer Software-Entwicklung Kunden andere Erwartungen an Software stellen: Statt für Arbeitszeit werde künftig stärker für messbare Ergebnisse bezahlt, beispielsweise anhand der Zahl gelöster Tickets. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/9f/9d/9f9d8357928662c1173bad86e63f0fb0/0126749087v2.jpeg "Miss Magic: Für das aktuelle vom KITCar-Team für die Cognitive Autonomous Driving Challenge entwickelte selbstfahrende Modellfahrzeug musste das zugrunde liegende Embedded-System komplett umgestellt werden. Zum Einsatz kamen die Open-Source-Systeme FreeRTOS und micro-ROS. Dabei musste das mit Multithreading unerfahrene Team umfassende Analysem am System durchführen. (Bild: KIT)")
:quality(80)/p7i.vogel.de/wcms/27/b9/27b9cfbb678630047f85e1adc55f7df7/0114455762.jpeg "Bild 1. Unterschiedliche Verarbeitungszeiten und Garantien für eine bestimmte Echtzeit-Task (Bild: LDRA)")
:quality(80)/p7i.vogel.de/wcms/4d/96/4d9621a180cfee96ba85d2da83163461/0105948132.jpeg "Eine effektive Verwaltung und nahtlose Orchestrierung verschiedener Softwarekomponenten auf einem einzigen SoC kann auf vielfältige Weise erreicht werden. (Bild: Siemens Software )")
:quality(80)/p7i.vogel.de/wcms/34/05/3405327567eb345e9c0c326a590cd9ae/0105886699.jpeg "Mithilfe der UDE 2022 können Entwickler alle Funktionseinheiten aus einer Umgebung heraus ansprechen. Kerne lassen sich gemeinsam, in Gruppen oder einzeln debuggen. (Bild: PLS)")
:quality(80)/p7i.vogel.de/wcms/22/89/22896600c7f19a5813fa824ee8207dd4/0122524970v2.jpeg "Ein halbautomatischer Webstuhl des französischen Erfinders Basile Bouchon aus dem Jahr 1725, zu sehen im Musée des arts et métiers, Paris. Die Löcher im Papierband gaben vor, welche Nadelöhre gehoben wurden, durch die das Muster der nächsten Reihe im Webstuhl zu laufen hatte. Je nach gewünschten Muster konnten die Lochbänder ausgewechselt werden - das Prinzip programmierbarer Maschinen war geboren. (Bild: Basile Bouchon 1725 loom / Dogcow / CC BY-SA 3.0)")
:quality(80)/p7i.vogel.de/wcms/e7/cf/e7cf5a22f39eddc3235f047c566b747e/0122159010v1.jpeg "Abstraktionsschichten (Symbolbild) (Bild: KI-generiert / DALL-E)")
:quality(80)/p7i.vogel.de/wcms/43/c4/43c4067994de48347a260c6191e88528/0103046501v1.jpeg "(Logo: Rust Foundation)")
:quality(80)/p7i.vogel.de/wcms/74/a1/74a1fcd5d60af69422390e97fbf77dcd/0109296819.jpeg "Das war der ESE Kongress 2022. (Bild: Elisabeth Wiesner)")
Machine Learning – so finden Sie den richtigen Algorithmus
Intelligente, selbstlernende Maschinen sind elementarer Bestandteil der Industrie 4.0. Damit Machine Learning auch bei zunehmender Komplexität erfolgreich eingesetzt werden kann, ist die Wahl des passenden Algorithmus ausschlaggebend. Entscheidungsbäume sind hier ein probates Mittel, um schnell den Weg zum richtigen Ansatz zu finden.
Anbieter zum Thema
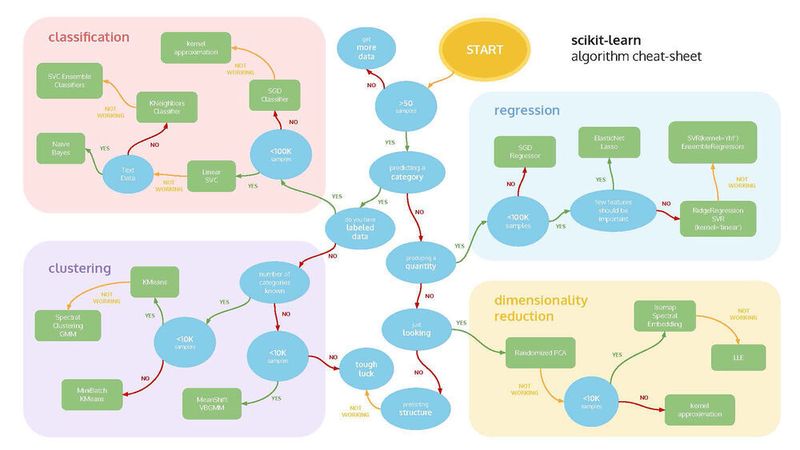
Die größte Herausforderung im Bereich Machine Learning in der Qualitätssicherung ist die Datenlage. Bei Bilddaten zählt vor allem die Quantität bei hinreichender Qualität. Das bedeutet, die Daten müssen eine ausreichende Auflösung haben, um die Klassen optisch unterscheiden zu können. Zu berücksichtigen sind dabei Reflektionen, Perspektive und Schattierungen. Zudem sollten die Beispieldaten jeder Klasse – das heißt, je Fehlertyp sowie Bilddaten mit und ohne Defekt – ausgewogen und in hoher Menge verfügbar sein.
Bei Maschinendaten sind die Qualitätskriterien etwas anders: Ist die Messfrequenz ausreichend? Sind Fremdeinflüsse wie Vibration, beispielsweise durch Nachbarmaschinen, minimiert? Ist der Zusammenhang von Betriebsdaten und Sensordaten nachvollziehbar? Optimalerweise sind hier historische Daten von Fehlerzuständen ausreichend. Insgesamt entscheidet sowohl die Qualität und Quantität der Daten als auch die zugrundeliegende kausale Abhängigkeit der Einflussgrößen und Zielgrößen darüber, inwieweit die automatische Qualitätssicherung beziehungsweise die Erkennung von Defekten und Fehlern gelingt. Zugleich entscheiden die Daten aber auch darüber, welche Algorithmen angewendet werden müssen, um die gewünschten Ergebnisse zu erzielen.
Für Deep-Learning-Algorithmen ist, sofern nicht vortrainierte Modelle verwendet werden können, häufig eine große Menge Beispieldaten notwendig, um überhaupt Zusammenhänge aus den Daten erlernen zu können. Der Einsatz von Deep Learning bietet sich dann an, wenn folgende Indikatoren zutreffend sind: Zum einen nämlich dann, wenn die wesentlichen Unterscheidungsmerkmale der Klassen nicht ohne Weiteres von einem Menschen in für den Computer verständliche Symbolik (Zahlen) gebracht werden kann. Zum anderen ist Deep Learning anwendbar, wenn die Daten ein komplexes Format aufweisen, es beispielsweise um Bilder oder Sprache geht. Aber auch dann, wenn viele Daten oder ein vortrainiertes Modell zur Verfügung stehen oder kein explizites Domänenwissen vorhanden ist.
Anwendungen mit deutlich kleineren Datenmengen werden häufig mithilfe des klassischen Machine Learning unter Einsatz von manueller Merkmalsextraktion (Feature Engineering) von Domänenexperten umgesetzt. Hier gibt es allerdings eine hohe Anzahl verschiedener Ansätze, die insgesamt die Komplexität auf Seiten des personellen (Domänenexperte) deutlich in die Höhe treibt.
Den richtigen Algorithmus finden
Machine Learning, Deep Learning und Künstliche Intelligenz – auf dem Weg hin zum passenden Algorithmus sind die relevanten Aspekte in den Entscheidungen die Menge an Beispieldaten (sind ausreichend Beispieldaten für Deep Learning vorhanden?) sowie die Kennzeichnung (Labeling) der Maschinendaten. (Geht es um Supervised oder Unsupervised Learning?)
Ebenso ist zu unterscheiden, ob beispielsweise eine Vorhersage kontinuierlicher Werte (Regression), eine Kategorisierung (Classification) oder eine Erkennung ungewöhnlicher Messwerte (Anomalien) durchgeführt werden soll. Konkret bedeutet das beispielsweise: Soll der Algorithmus eine Kategorisierung vornehmen, also etwa anhand eines Bildes zwischen verschiedenen Fehlertypen unterscheiden oder geht es um die Prognose eines Zahlenwertes, wie der Schätzung der Restlebenszeit eines Bauteils anhand von Sensordaten? Oder müssen unnatürliche Abweichungen der Daten vom Normalzustand erkannt werden, wie eine ungewöhnliche Korrelation von Vibration und Betriebstemperatur einer Maschine in einer normalen Produktionssituation?
Der Entscheidungsbaum als Lösungsansatz
Um herauszufinden, welcher Algorithmus nun der richtige ist, führt häufig der Weg an empirischen Ansätzen nicht vorbei. Da es sich bei Künstlicher Intelligenz und im Speziellen bei Machine Learning um ein groß gewachsenes Sortiment an Algorithmen handelt, kann es hilfreich sein, sich anhand der Charakteristiken Stück für Stück an den geeigneten Algorithmus heranzutasten. Dieser Weg beschreibt eine Verzweigung von Entscheidungen – einen sogenannten Entscheidungsbaum. Am Schluss des Entscheidungsbaums stehen mögliche Algorithmen, die bei der Datenverarbeitung helfen können. Dennoch spielen Erfahrungswerte weiterhin eine große Rolle und können beispielsweise die Anzahl der zu untersuchenden Ansätze deutlich reduzieren.
Chancen für die Qualitätssicherung
In der produzierenden Industrie wird Deep Learning sehr häufig im Bereich der visuellen Qualitätskontrolle und Fehlererkennung eingesetzt und verdrängt schrittweise das klassische, regelbasierte Vorgehen im Computer Vision. So findet Deep Learning beispielsweise Anwendung in der automatisierten Erkennung und Ausschleusung defekter Solar-Panels in der Solarindustrie. In der Medizinbranche werden Tabletten oder medizinisches Equipment auf Beschädigungen oder Einschlüsse in Behältnissen geprüft.
Trotz aller Mühen kann als Resultat herauskommen, dass mit den vorhandenen Daten keine ausreichenden Ergebnisse zu erzielen sind. Damit dieser Fall frühzeitig erkannt und die Aufwände minimal bleiben, muss ein erfahrenes Team die jeweiligen Fälle zu Beginn richtig bewerten und die Realisierbarkeit analysieren.
Der Entscheidungsbaum bietet dann eine effiziente Möglichkeit, den Weg von der Wahl des richtigen Algorithmus bis hin zum Start des Machine-Learning-Prozesses zu beschleunigen. Denn durch eine sorgfältige Vorbereitung und eindeutige Definition der benötigten Ergebnisse mithilfe des Entscheidungsbaums im Voraus, können unnötige Testreihen und Fehlversuche umgangen werden.

Der Trend der automatischen Qualitätssicherung wird sich deshalb nicht aufhalten lassen. Allein in China gibt es Produktionsstätten, in denen mehr als 10.000 Mitarbeiter nur für die Qualitätssicherung zuständig sind. Mithilfe des Entscheidungsbaum kann der richtige Machine-Learning-Algorithmus, der die automatisierte Ausschleusung defekter Teile ermöglicht, schnell gefunden werden. Der Einsatz des Entscheidungsbaums bietet also eine große Chance für die Qualitätssicherung und wird in vielen Fällen sehr genau untersucht.
Dieser Beitrag stammt von unserem Partnerportal BigData-Insider.de.
(ID:46502235)
:quality(80)/p7i.vogel.de/wcms/0d/e8/0de88d8542d1b2b5deddf20789bccc2c/0130537290v1.jpeg "Menschliches Wissen, künstliche Intelligenz: Intelligente Datenverarbeitung direkt am Einsatzort verlangt nach dem Zusammenspiel von KI, Hardware-Know-how und konkreter Anwendungserfahrung. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/2e/b2/2eb2a82d215c72f59c1fde532c092e87/0131010297v2.jpeg "MRT-Bilderkennungssystem: Gerade in der Medizintechnikkann der Einsatz von KI in einem Embedded Sytsem massive Vorzüge Bbringen. Umso mehr kommt es dabei aber auch auf die Zuverlässigkeit der Tests an, um Safety-Standards einzuhalten. (Bild: Magnific / Yaroslav Astakhov)")