:quality(80)/p7i.vogel.de/wcms/b8/20/b8203d9f2b6f6e61bff6c3fda15042d3/0128235802v2.jpeg "Die Forschenden aus dem Lehrstuhl für Robotik, Künstliche Intelligenz und Echtzeitsysteme testen die neue Architektur am Teststand der TUM. Im Bild (von links nach rechts): Chengdong Wu, Nils Purschke und Sven Kirchner. (Bild: besser 3 / TU München)")
:quality(80)/p7i.vogel.de/wcms/79/90/79901d8c1934b11223a53cb900b1aa85/das-20building-2092-20bei-20der-20microsoft-zentrale-20in-20redmond-20--20quelle-20coolcaesar-20via-20wikimedia-20commons-5184x2915v1.jpeg "Das Building 92 bei der Microsoft-Zentrale in Redmond. (Wikimedia Commons)")
:quality(80)/p7i.vogel.de/wcms/31/92/3192d2bddbdb052afd8904128dd7aec1/0123884994v2.jpeg "Projekte zur Entwicklung von Embedded-Systemen, wie auch die Systeme selbst, werden zunehmend komplexer. Modellbasiertes System-Engineering (MBSE) soll dabei helfen, diese zunehmende Komplexität in den Griff zu bekommen. Doch wann stößt das Prinzip an seine Grenzen? (Bild: KI-generiert / DALL-E)")
:quality(80)/p7i.vogel.de/wcms/b0/42/b04293b683f177fa6c781c1e00e1770f/0122968330v2.jpeg "Betrieb, Wartung, Updates: Während der Lebensdauer eines Embedded-Systems sind mehrere Lebenszyklus-Iterationen zu berücksichtigen. (Bild: © metamorworks – stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/ba/d7/bad734452b1b8360591396b49da37b72/0130644400v1.jpeg "Die Begriffe Echtzeit und Virtualisierung erscheinen zunächst widersprüchlich, da sie auch aus den konträren Domänen OT (Operational Technology) und IT (Information Technology) stammen. Virtualisierung bedeutet aber im Wesentlichen die Entkopplung einer bestimmten Applikation von der zugrunde liegenden Hardware, was keinen direkten Kontrast zu Echtzeit bedeuten muss. Dieser Artikel erläutert die verschiedenen technischen Möglichkeiten, eine Applikation von der Hardware zu entkoppeln, um anschließend deren individuelle Tauglichkeit zum Ablauf echtzeitkritischer Systeme zu evaluieren. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/cc/53/cc53ebfd9f45b28eb918a8098b63846b/0127825678v1.jpeg "Im zweiten und letzten Teil der Artikelserie zu Latenzen wird gezeigt, wie sich Latenz mit dem richtigen RTOS, Interrupt-Optimierung, Low-Level-Code und Co-Design gezielt senken lässt. (Bild: Green Hills Software)")
:quality(80)/p7i.vogel.de/wcms/ac/ea/acea3ca6c15e0bd261c8bde5d3fe7bfb/0127825678v2.jpeg "Bild 1: Um Latenzzeiten in echtzeitkritischen Systemen verringern zu können braucht es erst einmal Verständnis, wie diese entstehen. Im ersten Teil unserer zweiteiligen Reihe werden die Schlüsselfaktoren untersucht, die sowohl auf Hardware- als auch auf Software-Ebene zur Latenz beitragen. (Bild: Green Hills Software)")
:quality(80)/p7i.vogel.de/wcms/93/d9/93d9211463a0af86eff0b83c359cd880/0127528428v1.jpeg "Mit Aufnahme von PREEMPT_RT in den Mainline-Kernel 6.12 wurde Linux vor etwa einem Jahr nativ echtzeitfähig. Wie kam es zu dieser Entwicklung- und wie lassen sich die Echtzeiteigenschaften von Linuc evaluieren? (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d9/c1/d9c121f0680f16e547502038f5c26481/0130027942v2.jpeg "Laut dem aktuellen State of Automotive Software Development Report von Perforce verwenden bereits 71 % der befragten Unternehmen KI in der Entwicklung von Fahrzeugsoftware. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/75/3d/753d0fa44b344d363e25c91dc0752635/0129134302v2.jpeg "Volle Säle, reger Austausch: Trotz einer spürbaren Konjunkturflaute gerade im Automotive-Bereich fanden sich erneut um die 1000 Teilnehmer in der Stadthalle Sindelfingen zum ESE Kongress 2025 ein. (Bild: Nicolas Det)")
:quality(80)/p7i.vogel.de/wcms/ef/9a/ef9a10566eaa807a8fdad9cbff80246f/0126533084v1.jpeg "Die wachsende Bedeutung agentischer KI wird früher oder später zu einer Abkehr von klassischer UI-Interaktion führen: Werden Business-Anwendungen bald unsichtbar und ihr Branding für Anwender irrelevant? (Bild: © lassedesignen - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/47/f5/47f5a305c48bfcaf3daae7e6b7478a0f/0131065910v2.jpeg "Rust hält Einzug in die Fahrzeugsoftware und adressiert vor allem Speicher- und Sicherheitsrisiken in vernetzten Steuergeräten. Für OEMs und Zulieferer stellt sich damit weniger die Frage „Rust oder C“, sondern welche Komponenten zuerst von einem Wechsel profitieren. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/a9/a8/a9a87353e49fb7432ce35aef31d06ad6/0130134372v2.jpeg "Der Umstand, dass die Einreichenden für die Erstellung von Programmcode dank KI-gestützter Tools oder generativer KI selbst kein technisches Sachverständnis benötigen, hat zu einer Flut an schlampigem und unsicheren Pull Requests und Submits bei Open-Source-Projekten geführt, mit der die meist freiwilligen Maintainer kaum noch zurecht kommen. Die Linux Foundation hat nun 12,5 Millionen US-Dollar an Fördermitteln eingefahren, um diesen Umstand zu adressieren und Security in Open-Source-Projekten zu unterstützen. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/1e/b2/1eb228a11ff793648167b84e30da4eb3/0129529708v2.jpeg "Speicherfehler wie Pufferüberläufe oder Use-After-Free gefährden die Stabilität von Fahrzeugsoftware. Formale Verifizierung hilft dabei, aus getesteter Software nachweislich sichere Systeme zu machen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/df/0a/df0a16a8a74519cf7e4ae26b468a8326/0129511289v2.jpeg "Wenn Sicherheits- und Bequemlichkeitsansprüche kollidieren: Sicherheitsforscher der ETH Zürich haben gravierende Mängel bei drei führenden Passwort-Managern festgestellt. Das Beispiel zeigt, wie der Wunsch nach besserer Usability in Widerspruch mit einer erhöhrten Security geraten kann. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/23/23/2323167fce16d7a31011ac17a97933c9/0129855253v2.jpeg "C ist als Programmiersprachen seit Jahrzehnten etabliert, doch bestimmte Anfängerfehler finden sich immer wieder. Vom Vergessen des NULL-Terminators bis zum Abgleich von C-Strings: Dies sind die häufigsten Fehltritte von C-Einsteigern. (Bild: IAR Systems)")
:quality(80)/p7i.vogel.de/wcms/5f/e0/5fe00181ea62f890f53af36d03782612/0129630465v1.jpeg "KI sei längst nicht mehr nur Nice-to-have, sondern ein entscheidender Faktor dafür, welche Sprachen, Frameworks und Tools Entwickler bevorzugten. (Bild: GitHub)")
:quality(80)/p7i.vogel.de/wcms/6f/92/6f92cb791d67b866650a432e847ad8f2/0129693241v2.jpeg "Eine Karte mit Programmcode, wie sie in Unterrichtseinheiten für COBOL-Programmierung auf einem IBM System/360 Mainframe eingesetzt wurde. Die über 65 Jahre alte Programmiersprache COBOL ist vor allem bei Legacy-Anwendungen im Bank- und Versicherungswesen noch fest verankert, und deren Modernisierung aufwändig und teuer. Laut Anthropic lässt sich dieser Aufwand nun mit dem KI-Tool Claude Code leicht automatisieren. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f3/0e/f30ed4c0e762a250c39013170f3d154a/0131041847v1.jpeg "Ein früher IBM-PC, nebst einem Teil der Ausdrucke, die den Quellcode zu x86-DOS enthalten. (Bild: Rich Cini, Microsoft)")
:quality(80)/p7i.vogel.de/wcms/2e/b2/2eb2a82d215c72f59c1fde532c092e87/0131010297v2.jpeg "MRT-Bilderkennungssystem: Gerade in der Medizintechnikkann der Einsatz von KI in einem Embedded Sytsem massive Vorzüge Bbringen. Umso mehr kommt es dabei aber auch auf die Zuverlässigkeit der Tests an, um Safety-Standards einzuhalten. (Bild: Magnific / Yaroslav Astakhov)")
:quality(80)/p7i.vogel.de/wcms/44/a7/44a7069736629cbbfa41b74af865ec67/0130322397v4.jpeg "Bild 1: Das Testen von Software wird beim SDV immer umfangreicher. Die Tests lassen sich aber auf virtuelle ECUs verlagern, noch bevor die realen ECUs zur Verfügung stehen. (Bild: Intellias)")
:quality(80)/p7i.vogel.de/wcms/eb/23/eb23785d23e0a13df6f6344f6d880bd0/0129487941v1.jpeg "Illustration eines \"In-the-Loop\" Testansatzes: Struktur eines Reglers (links) und Realisierung eines Reglers auf einem Steuergerät (rechts). (Bild: embeff)")
:quality(80)/p7i.vogel.de/wcms/71/8c/718c0df3cae4339bb3ea0b799b53e1cd/0131015301v2.jpeg "Dank KI-Tools können heute auch Laien zu Softwareentwicklern werden. Dennoch haben letztlich Informatikkenntnisse den größten Einfluss darauf, wie gut diese beim sogenannten Vibe Coding abschneiden. Aber auch auf generelle Schreibfähigkeiten kommt es an. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/b1/21/b12113e8d5357060593e78ad3e396773/0130960706v1.jpeg "KI verändert den Alltag und den Arbeitsplatz. Dabei sind die Deutschen sehr gespalten, was den Einsatz künstlicher Intelligenz im Beruf betrifft. Bitkom-Präsident Dr. Ralf Wintergerst spricht sich dennoch für eine verstärkte Offenheit gegenüber des Einsatzes aus. Schließlich habe gerade der Nutzen von KI in Simulation und Modellierung die Entwicklung neuer Fahrzeuge in der chinesischen Automobilbranche drastisch verkürzt. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/0d/e8/0de88d8542d1b2b5deddf20789bccc2c/0130537290v1.jpeg "Menschliches Wissen, künstliche Intelligenz: Intelligente Datenverarbeitung direkt am Einsatzort verlangt nach dem Zusammenspiel von KI, Hardware-Know-how und konkreter Anwendungserfahrung. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/4c/f0/4cf066b46a5fcfc430a2454a5e82e801/0129279386v1.jpeg "Der Entwickler des beliebten Open-Source-Texteditors Notepad++ hat bestätigt, dass Hacker die Software gekapert haben, um den Nutzern im Laufe mehrerer Monate im Jahr 2025 bösartige Updates zu liefern. Die Spur der Angreifer führt nach China. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/9f/9d/9f9d8357928662c1173bad86e63f0fb0/0126749087v2.jpeg "Miss Magic: Für das aktuelle vom KITCar-Team für die Cognitive Autonomous Driving Challenge entwickelte selbstfahrende Modellfahrzeug musste das zugrunde liegende Embedded-System komplett umgestellt werden. Zum Einsatz kamen die Open-Source-Systeme FreeRTOS und micro-ROS. Dabei musste das mit Multithreading unerfahrene Team umfassende Analysem am System durchführen. (Bild: KIT)")
:quality(80)/p7i.vogel.de/wcms/27/b9/27b9cfbb678630047f85e1adc55f7df7/0114455762.jpeg "Bild 1. Unterschiedliche Verarbeitungszeiten und Garantien für eine bestimmte Echtzeit-Task (Bild: LDRA)")
:quality(80)/p7i.vogel.de/wcms/4d/96/4d9621a180cfee96ba85d2da83163461/0105948132.jpeg "Eine effektive Verwaltung und nahtlose Orchestrierung verschiedener Softwarekomponenten auf einem einzigen SoC kann auf vielfältige Weise erreicht werden. (Bild: Siemens Software )")
:quality(80)/p7i.vogel.de/wcms/34/05/3405327567eb345e9c0c326a590cd9ae/0105886699.jpeg "Mithilfe der UDE 2022 können Entwickler alle Funktionseinheiten aus einer Umgebung heraus ansprechen. Kerne lassen sich gemeinsam, in Gruppen oder einzeln debuggen. (Bild: PLS)")
:quality(80)/p7i.vogel.de/wcms/22/89/22896600c7f19a5813fa824ee8207dd4/0122524970v2.jpeg "Ein halbautomatischer Webstuhl des französischen Erfinders Basile Bouchon aus dem Jahr 1725, zu sehen im Musée des arts et métiers, Paris. Die Löcher im Papierband gaben vor, welche Nadelöhre gehoben wurden, durch die das Muster der nächsten Reihe im Webstuhl zu laufen hatte. Je nach gewünschten Muster konnten die Lochbänder ausgewechselt werden - das Prinzip programmierbarer Maschinen war geboren. (Bild: Basile Bouchon 1725 loom / Dogcow / CC BY-SA 3.0)")
:quality(80)/p7i.vogel.de/wcms/e7/cf/e7cf5a22f39eddc3235f047c566b747e/0122159010v1.jpeg "Abstraktionsschichten (Symbolbild) (Bild: KI-generiert / DALL-E)")
:quality(80)/p7i.vogel.de/wcms/43/c4/43c4067994de48347a260c6191e88528/0103046501v1.jpeg "(Logo: Rust Foundation)")
:quality(80)/p7i.vogel.de/wcms/74/a1/74a1fcd5d60af69422390e97fbf77dcd/0109296819.jpeg "Das war der ESE Kongress 2022. (Bild: Elisabeth Wiesner)")
Methoden der Linearen Regressionsanalyse
Regressionsanalysen dienen dazu, Prognosen zu erstellen und Abhängigkeiten in Beziehungen aufzudecken. Will ein Smartphone-Hersteller herausfinden, mit welchem Preis er in welchem Kundenkreis welchen Umsatz erzielen kann, so kennt er nur eine Variable – den Preis – aber nicht die anderen Variablen. Heute gibt es eine große Zahl solcher Verfahren, denn sie werden für zahlreiche Zwecke benötigt, etwa in der Epidemiologie.
Anbieter zum Thema
Bei Regressionsanalysen werden Beziehungen zwischen einer abhängigen und mehreren unabhängigen Variablen modelliert. Damit lassen sich Zusammenhänge quantitativ beschreiben oder Werte der abhängigen Variablen vorhersagen.
Eine weitere Anwendung besteht in der für jede moderne Kommunikation essenziellen Trennung zwischen Signal (Funktion) und Rauschen (Fehler) sowie der Abschätzung des dabei gemachten Fehlers, der Störfunktion. Weitere einführende Bemerkungen sind in dem Artikel von BigData-Insider über die Einfache Lineare Regression zu finden.
Multiple lineare Regression
Die multiple lineare Regression wird auch „mehrfache lineare Regression“ (kurz: MLR) oder „lineare Mehrfachregression“ genannt. Sie ist ein regressionsanalytisches Verfahren und ein Spezialfall der linearen Regression. Die MLR versucht, eine beobachtete abhängige Variable durch mehrere unabhängige Variablen zu erklären. Das dazu verwendete Modell ist linear in den Parametern, wobei die abhängige Variable eine Funktion der unabhängigen Variablen ist. Diese Beziehung wird durch eine additive Störgröße überlagert. Die MLR stellt somit eine Verallgemeinerung der ELR bezüglich der Anzahl der Regressoren dar.

Bei der multiplen linearen Regression werden mehrere unabhängige Variablen oder Funktionen der unabhängigen Variablen berücksichtigt. Wird zum Beispiel der Term x hoch 2 zur vorigen Regression hinzugefügt, so ergibt sich: yi = β0 + β1xi + β2xi2 + eii = 1, ..., p. Dabei ist β der unbekannte Parameter. Obwohl der Ausdruck auf der rechten Seite quadratisch in der unabhängigen Variable ist, ist der Ausdruck linear in den Parametern β1, β2 und β3, und . Damit ist dies auch eine lineare Regressionsgleichung. Zur Bestimmung der Modellparameter wird die Methode der kleinsten Quadrate verwendet.
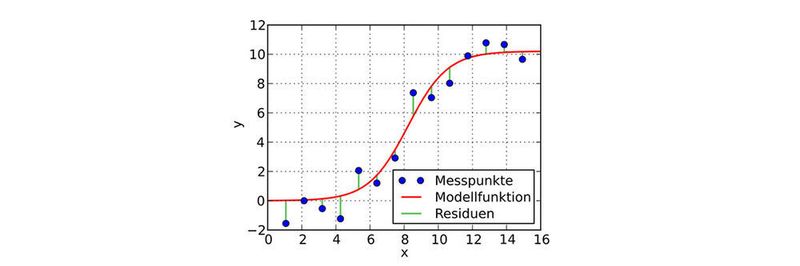
Die wesentliche Voraussetzung an das MLR besteht darin, dass es bis auf die Störgröße ε [Epsilon] das „wahre Modell“ beschreibt. Das zugrundeliegende „wahre Modell“ ist das eigentliche Populationsmodell, welches die Zielgröße und die relevanten Einflussgrößen in Beziehung zueinander setzt. Diese Beziehung wird durch eine additive Störgröße überlagert, für die angenommen wird, dass sie einen Erwartungswert von Null aufweist. Die grundlegende Annahme des Modells ist, dass es linear in den Parametern ist.
 und geschätzter Regressionsgerade (rot) sowie wahrer Störgröße und geschätzter Störgröße (Residuum).")
Im Modell wird in der Regel nicht genau spezifiziert, von welcher Art die Störgröße ε ist; sie kann beispielsweise von zusätzlichen Faktoren oder Messfehlern herrühren. Jedoch nimmt man als Grundvoraussetzung an, dass dessen Erwartungswert (in allen Komponenten) 0 ist (Annahme 1). Diese Annahme bedeutet, dass das Modell grundsätzlich für korrekt gehalten und die beobachtete Abweichung als zufällig angesehen wird oder von vernachlässigbaren äußeren Einflüssen herrührt.
Typisch ist die Annahme, dass die Komponenten des Vektors unkorreliert sind (Annahme 2) und dieselbe Varianz σ2 [kleines Sigma] besitzen (Annahme 3), wodurch sich mithilfe von Verfahren wie der Methode der kleinsten Quadrate (s.o.) einfache Schätzer für die unbekannten Parameter β und σ2 ergeben. Die Methode wird daher auch (multiple lineare) KQ-Regression bzw. KQ-Schätzer genannt. Es ist das Standardverfahren zur mathematischen Ausgleichsrechnung.
Der F-Test
Der globale F-Test, auch Globaltest, Gesamttest, Test auf Gesamtsignifikanz eines Modells, F-Test der Gesamtsignifikanz, Test auf den Gesamtzusammenhang eines Modells genannt, stellt eine globale Prüfung der Regressionsfunktion dar. Mit dem F-Test wird eine Kombination von linearen (Gleichungs-) Hypothesen geprüft und somit, ob mindestens eine Variable einen Erklärungsgehalt für das Modell liefert und das Modell somit als Gesamtes signifikant ist. Falls diese Hypothese verworfen wird, ist das Modell nutzlos. Diese Variante des F-Tests ist die gebräuchlichste Anwendung des F-Tests. Beim Spezialfall der Varianzanalyse kann man Unterschiede zwischen zwei Stichproben aufdecken.
Der Test geht auf einen der bekanntesten Statistiker, Ronald Aylmer Fisher (1890 bis 1962) zurück. Er formulierte auch den verbreiteten T-Test.
Epidemiologie
In der Erfassung und Bekämpfung von Epidemien sind Stichproben von größter Bedeutung. Das Problem ist die Aufdeckung von Zusammenhängen und von Merkmalen, die signifikant sind. Die Stichproben dürfen daher nicht zu klein ausfallen.
Die Regressionsanalyse wurde schon früh genutzt, um den Zusammenhang zwischen Tabakrauchen und Krankheits- bzw. Sterblichkeitsrate von Rauchern zu erfassen und zu bewerten. Während in den 1920er-Jahren Werbekampagnen gewöhnliche Zigaretten den US-amerikanischen Frauen als „Fackeln der Freiheit“ anpriesen, dachte wohl keiner – zumindest nicht offiziell – dass Rauchen erhebliche Gesundheitsrisiken barg und birgt.
Doch Beobachtungsstudien, die Regressionsanalyse nutzten, entdeckten den o. g. Zusammenhang. Um zufällige Korrelationen bei der Analyse von Beobachtungsdaten auszuschließen, integrieren Forscher üblicherweise verschiedene Variablen in ihre Regressionsmodelle, zusätzlich zu ihrer primären unabhängigen Variable: das Rauchen etwa. Die abhängige Variable ist Lebensdauer (in Jahren), aber zusätzlich integrieren die Forscher Variablen wie Ausbildungsniveau und Einkommensklasse, also sozioökonomische (und ernährungsmäßige) Faktoren. Diese Störfaktoren wollen sie ausschließen, um so den primären Faktor, das Rauchen, zu determinieren.
Sämtliche Störfaktoren auszuschließen, ist in einer empirischen Untersuchung kaum jemals möglich. Beispielsweise könnte ein hypothetisches Gen die Sterblichkeitsrate beeinflussen oder Leute dazu bringen, mehr zu rauchen. Um solche Störfaktoren aufzuspüren und zu eliminieren, werden häufig zufallsbasierte, kontrollierte Versuchsreihen ausgeführt. Falls es kausale Zusammenhänge gibt, fördern diese Stichproben eher Beweise zutage als Regressionsanalysen von Beobachtungsdaten. Lassen sich jedoch kontrollierte Versuche nicht realisieren, kann man Varianten der MLR wie etwa Instrumentvariablenschätzung nutzen, um kausale Zusammenhänge in Beobachtungsdaten aufzuspüren.
:quality(80)/images.vogel.de/vogelonline/bdb/1745300/1745348/original.jpg "Bestmögliche Gerade durch die „Punktwolke“ einer Messung (gemeinfrei)")
Mit einfacher Regressionsanalyse Mittelwerte in Prognosen ermitteln
:quality(80)/images.vogel.de/vogelonline/bdb/1592200/1592281/original.jpg "Kernel-Maschinen werden verwendet, um nichtlinear trennbare Funktionen zu berechnen, um so eine linear trennbare Funktion höherer Ordnung zu erhalten. (Kernel Machine.svg / Alisneaky, svg version by User:Zirguezi / CC BY-SA 4.0)")
Optimale Clusteranalyse und Segmentierung mit dem k-Means-Algorithmus
:quality(80)/images.vogel.de/vogelonline/bdb/1602200/1602206/original.jpg "Kernidee von LOF ist, die lokale Dichte eines Punktes mit der seiner Nachbarn zu vergleichen- (gemeinfrei)")
So deckt der Local Outlier Factor Anomalien auf
Dieser Beitrag stammt von unserem Partnerportal Bigdata-Insider.de.
(ID:46867855)
:quality(80)/p7i.vogel.de/wcms/23/23/2323167fce16d7a31011ac17a97933c9/0129855253v2.jpeg "C ist als Programmiersprachen seit Jahrzehnten etabliert, doch bestimmte Anfängerfehler finden sich immer wieder. Vom Vergessen des NULL-Terminators bis zum Abgleich von C-Strings: Dies sind die häufigsten Fehltritte von C-Einsteigern. (Bild: IAR Systems)")
:quality(80)/p7i.vogel.de/wcms/2e/b2/2eb2a82d215c72f59c1fde532c092e87/0131010297v2.jpeg "MRT-Bilderkennungssystem: Gerade in der Medizintechnikkann der Einsatz von KI in einem Embedded Sytsem massive Vorzüge Bbringen. Umso mehr kommt es dabei aber auch auf die Zuverlässigkeit der Tests an, um Safety-Standards einzuhalten. (Bild: Magnific / Yaroslav Astakhov)")