:quality(80)/p7i.vogel.de/wcms/b5/ae/b5ae6808f29fc09bf61b47807604bcf4/0131740517v2.jpeg "Wenn KI Aktuatoren steuert, wird Edge AI zur Physical AI. Hinsichtlich der Software-Entwicklung kommt es dabei nicht nur auf die Modelleistung an: gerade Safety, Compliance und eine zertifizierte Toolchain werden hier zu entscheidenden Faktoren. (Bild: @homaappliances/Unsplash)")
:quality(80)/p7i.vogel.de/wcms/b8/20/b8203d9f2b6f6e61bff6c3fda15042d3/0128235802v2.jpeg "Die Forschenden aus dem Lehrstuhl für Robotik, Künstliche Intelligenz und Echtzeitsysteme testen die neue Architektur am Teststand der TUM. Im Bild (von links nach rechts): Chengdong Wu, Nils Purschke und Sven Kirchner. (Bild: besser 3 / TU München)")
:quality(80)/p7i.vogel.de/wcms/79/90/79901d8c1934b11223a53cb900b1aa85/das-20building-2092-20bei-20der-20microsoft-zentrale-20in-20redmond-20--20quelle-20coolcaesar-20via-20wikimedia-20commons-5184x2915v1.jpeg "Das Building 92 bei der Microsoft-Zentrale in Redmond. (Wikimedia Commons)")
:quality(80)/p7i.vogel.de/wcms/31/92/3192d2bddbdb052afd8904128dd7aec1/0123884994v2.jpeg "Projekte zur Entwicklung von Embedded-Systemen, wie auch die Systeme selbst, werden zunehmend komplexer. Modellbasiertes System-Engineering (MBSE) soll dabei helfen, diese zunehmende Komplexität in den Griff zu bekommen. Doch wann stößt das Prinzip an seine Grenzen? (Bild: KI-generiert / DALL-E)")
:quality(80)/p7i.vogel.de/wcms/da/34/da343cfac1c945d425a8c650abd7c448/0131414071v2.jpeg "Softwaredefinierte Systeme müssen auch dann zuverlässig zusammenarbeiten, wenn Netzwerke schwanken oder ausfallen. RTI Connext und der Persistence Service können dafür sorgen, konsistente Datenflüsse zu gewährleisten. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/ba/d7/bad734452b1b8360591396b49da37b72/0130644400v1.jpeg "Die Begriffe Echtzeit und Virtualisierung erscheinen zunächst widersprüchlich, da sie auch aus den konträren Domänen OT (Operational Technology) und IT (Information Technology) stammen. Virtualisierung bedeutet aber im Wesentlichen die Entkopplung einer bestimmten Applikation von der zugrunde liegenden Hardware, was keinen direkten Kontrast zu Echtzeit bedeuten muss. Dieser Artikel erläutert die verschiedenen technischen Möglichkeiten, eine Applikation von der Hardware zu entkoppeln, um anschließend deren individuelle Tauglichkeit zum Ablauf echtzeitkritischer Systeme zu evaluieren. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/cc/53/cc53ebfd9f45b28eb918a8098b63846b/0127825678v1.jpeg "Im zweiten und letzten Teil der Artikelserie zu Latenzen wird gezeigt, wie sich Latenz mit dem richtigen RTOS, Interrupt-Optimierung, Low-Level-Code und Co-Design gezielt senken lässt. (Bild: Green Hills Software)")
:quality(80)/p7i.vogel.de/wcms/ac/ea/acea3ca6c15e0bd261c8bde5d3fe7bfb/0127825678v2.jpeg "Bild 1: Um Latenzzeiten in echtzeitkritischen Systemen verringern zu können braucht es erst einmal Verständnis, wie diese entstehen. Im ersten Teil unserer zweiteiligen Reihe werden die Schlüsselfaktoren untersucht, die sowohl auf Hardware- als auch auf Software-Ebene zur Latenz beitragen. (Bild: Green Hills Software)")
:quality(80)/p7i.vogel.de/wcms/56/9b/569b4da4d1f2e4ce6f41918f86d00c04/0131738385v2.jpeg "Laut der Atlassian-Studie „State of Teams 2026“ verlieren Fortune-500-Unternehmen jedes Jahr schätzungsweise 161 Milliarden US-Dollar durch KI-bedingte Reibungsverluste. Das Problem ist mangelnde Koordination: 80 Prozent der Arbeit in Unternehmen findet innerhalb von Teams oder teamübergreifend statt, aber nur 24 Prozent der Führungskräfte legen ihre KI-Initiativen gezielt auf diese Zusammenarbeit aus. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/d9/c1/d9c121f0680f16e547502038f5c26481/0130027942v2.jpeg "Laut dem aktuellen State of Automotive Software Development Report von Perforce verwenden bereits 71 % der befragten Unternehmen KI in der Entwicklung von Fahrzeugsoftware. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/75/3d/753d0fa44b344d363e25c91dc0752635/0129134302v2.jpeg "Volle Säle, reger Austausch: Trotz einer spürbaren Konjunkturflaute gerade im Automotive-Bereich fanden sich erneut um die 1000 Teilnehmer in der Stadthalle Sindelfingen zum ESE Kongress 2025 ein. (Bild: Nicolas Det)")
:quality(80)/p7i.vogel.de/wcms/0d/9b/0d9be5033416dffb1b4f5cc050560a25/0131796023v2.jpeg "Vom Gateway zur Central Unit: Im SDV werden Fahrzeugfunktionen zentralisiert und müssen über klare Partitionierung, Isolation und Safety-Scope abgesichert werden. (Bild: Elektrobit)")
:quality(80)/p7i.vogel.de/wcms/8b/a7/8ba78f02e76e08a21fe98487faa35225/0131725834v1.jpeg "Die Neugründung eines KI-Sicherheitsinstituts soll insbesondere auf die digitale Souveränität Deutschlands einzahlen. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/2e/89/2e8965af7611ed0c0db93bdb9f973cbb/0131759111v1.jpeg "Fractal basiert auf einem neuen Konzept: dem „Outer Kernel“-Thread, der sich im Speicher eines Benutzerprozesses befindet, aber mit Kernel-Rechten ausgeführt wird. Entwicklerund MIT-Doktorand Joseph Ravichandran bezeichnet das resultierende Betriebssystem als das „Elektronenmikroskop der Betriebssysteme“. (Bild: MIT / Gabriel Maragaño)")
:quality(80)/p7i.vogel.de/wcms/41/c9/41c91ed48343a6014ddcd2aaa9029248/0130954766v2.jpeg "In welcher Programmiersprache wird Fahrzeug-Software geschrieben? Diese Frage rückt nunmehr in Bereiche, in denen über Architektur, Risiko und Zulassung entschieden wird. (Bild: frei lizensiert bei Pexels)")
:quality(80)/p7i.vogel.de/wcms/38/41/384121ebf647b1fc2149044fe5857c51/0131567723v2.jpeg "Microsoft plant, bis zum Release von C# 16 die Speichersicherheit der Programmiersprache grundlegend zu verbessert. Dabei orientiert sich das Entwicklerteam an Paradigmen, die aus Rust bekannt sind. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/47/f5/47f5a305c48bfcaf3daae7e6b7478a0f/0131065910v2.jpeg "Rust hält Einzug in die Fahrzeugsoftware und adressiert vor allem Speicher- und Sicherheitsrisiken in vernetzten Steuergeräten. Für OEMs und Zulieferer stellt sich damit weniger die Frage „Rust oder C“, sondern welche Komponenten zuerst von einem Wechsel profitieren. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/23/23/2323167fce16d7a31011ac17a97933c9/0129855253v2.jpeg "C ist als Programmiersprachen seit Jahrzehnten etabliert, doch bestimmte Anfängerfehler finden sich immer wieder. Vom Vergessen des NULL-Terminators bis zum Abgleich von C-Strings: Dies sind die häufigsten Fehltritte von C-Einsteigern. (Bild: IAR Systems)")
:quality(80)/p7i.vogel.de/wcms/bd/15/bd15e3adf9e8d2e15c1485d809078729/0131621839v2.jpeg "Sicherheitsforscher melden manipulierte Red-Hat-Pakete im npm-Registry. Betroffene Systeme, welche die befallenen Pakete heruntergeladen haben, gelten als direkt kompromittiert, weil der Schadcode schon bei der Installation ausgeführt wird. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f3/0e/f30ed4c0e762a250c39013170f3d154a/0131041847v1.jpeg "Ein früher IBM-PC, nebst einem Teil der Ausdrucke, die den Quellcode zu x86-DOS enthalten. (Bild: Rich Cini, Microsoft)")
:quality(80)/p7i.vogel.de/wcms/d2/e9/d2e9736dbd5b904cb34192c7b350e1d5/0131669814v2.jpeg "Unter dem Druck des Managements wiegt die schnelle Veröffentlichung von Software oft mehr als ihre Qualität. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/8a/09/8a094e681c2f4b9aefbeb7bd2732af4a/0131173224v1.jpeg "Unit-Tests in regulierten Branchen müssen mehr leisten als reine Fehlerprüfung. Der Artikel zeigt, wie GoogleTest bewertet wird und welche Rolle C/C++test CT dabei spielen kann. (Bild: Parasoft)")
:quality(80)/p7i.vogel.de/wcms/2e/b2/2eb2a82d215c72f59c1fde532c092e87/0131010297v2.jpeg "MRT-Bilderkennungssystem: Gerade in der Medizintechnikkann der Einsatz von KI in einem Embedded Sytsem massive Vorzüge Bbringen. Umso mehr kommt es dabei aber auch auf die Zuverlässigkeit der Tests an, um Safety-Standards einzuhalten. (Bild: Magnific / Yaroslav Astakhov)")
:quality(80)/p7i.vogel.de/wcms/44/a7/44a7069736629cbbfa41b74af865ec67/0130322397v4.jpeg "Bild 1: Das Testen von Software wird beim SDV immer umfangreicher. Die Tests lassen sich aber auf virtuelle ECUs verlagern, noch bevor die realen ECUs zur Verfügung stehen. (Bild: Intellias)")
:quality(80)/p7i.vogel.de/wcms/9f/9d/9f9d8357928662c1173bad86e63f0fb0/0126749087v2.jpeg "Miss Magic: Für das aktuelle vom KITCar-Team für die Cognitive Autonomous Driving Challenge entwickelte selbstfahrende Modellfahrzeug musste das zugrunde liegende Embedded-System komplett umgestellt werden. Zum Einsatz kamen die Open-Source-Systeme FreeRTOS und micro-ROS. Dabei musste das mit Multithreading unerfahrene Team umfassende Analysem am System durchführen. (Bild: KIT)")
:quality(80)/p7i.vogel.de/wcms/27/b9/27b9cfbb678630047f85e1adc55f7df7/0114455762.jpeg "Bild 1. Unterschiedliche Verarbeitungszeiten und Garantien für eine bestimmte Echtzeit-Task (Bild: LDRA)")
:quality(80)/p7i.vogel.de/wcms/4d/96/4d9621a180cfee96ba85d2da83163461/0105948132.jpeg "Eine effektive Verwaltung und nahtlose Orchestrierung verschiedener Softwarekomponenten auf einem einzigen SoC kann auf vielfältige Weise erreicht werden. (Bild: Siemens Software )")
:quality(80)/p7i.vogel.de/wcms/34/05/3405327567eb345e9c0c326a590cd9ae/0105886699.jpeg "Mithilfe der UDE 2022 können Entwickler alle Funktionseinheiten aus einer Umgebung heraus ansprechen. Kerne lassen sich gemeinsam, in Gruppen oder einzeln debuggen. (Bild: PLS)")
:quality(80)/p7i.vogel.de/wcms/22/89/22896600c7f19a5813fa824ee8207dd4/0122524970v2.jpeg "Ein halbautomatischer Webstuhl des französischen Erfinders Basile Bouchon aus dem Jahr 1725, zu sehen im Musée des arts et métiers, Paris. Die Löcher im Papierband gaben vor, welche Nadelöhre gehoben wurden, durch die das Muster der nächsten Reihe im Webstuhl zu laufen hatte. Je nach gewünschten Muster konnten die Lochbänder ausgewechselt werden - das Prinzip programmierbarer Maschinen war geboren. (Bild: Basile Bouchon 1725 loom / Dogcow / CC BY-SA 3.0)")
:quality(80)/p7i.vogel.de/wcms/e7/cf/e7cf5a22f39eddc3235f047c566b747e/0122159010v1.jpeg "Abstraktionsschichten (Symbolbild) (Bild: KI-generiert / DALL-E)")
:quality(80)/p7i.vogel.de/wcms/43/c4/43c4067994de48347a260c6191e88528/0103046501v1.jpeg "(Logo: Rust Foundation)")
:quality(80)/p7i.vogel.de/wcms/74/a1/74a1fcd5d60af69422390e97fbf77dcd/0109296819.jpeg "Das war der ESE Kongress 2022. (Bild: Elisabeth Wiesner)")
Machine Learning mit Python: Einführung in Amazon SageMaker
Amazon SageMaker ist ein von AWS vollständig verwalteter Service, der den gesamten Workflow von Machine Learning abdeckt. Anhand der SageMaker-Demo von AWS illustrieren wir die wichtigsten Zusammenhänge, Grundlagen und Funktionsprinzipien.
Anbieter zum Thema
Im ersten Teil unserer Serie zu Machine Learning mit Python haben wir uns die Grundlagen zum Erstellen eines Jupyter-Notebooks näher angesehen. Mit dem im ersten Abschnitt besprochenen Grundlagen wollen wir uns nun näher mit dem AWS-Service SageMaker befassen.
Für unsere ersten Experimente verwenden wir das MNIST-Dataset als Trainingsdaten. Bei der MNIST-Datenbank (Modified National Institute of Standards and Technology) handelt es sich um eine sehr große Datenbank handgeschriebener Ziffern, die üblicherweise zum Trainieren verschiedener Bildverarbeitungssysteme verwendet wird.
Die Datenbank wird auch häufig für Schulungen und Tests im Bereich des maschinellen Lernens (ML) verwendet. Erstellt wurde das Dataset durch „erneutes Mischen“ der Proben aus den ursprünglichen Datensätzen des NIST-Datasets.
Der Grund dafür ist, dass die Macher der Ansicht waren, dass der NIST-Trainingsdatensatz direkt nicht für Experimente mit maschinellem Lernen geeignet ist, weil er von Mitarbeitern des American Census Bureau und der Testdatensatz von amerikanischen Schülern stammt. In der MNIST-Datenbank wurden die Schwarzweißbilder des NIST auf eine Größe von 28 x 28 Pixeln mit Anti-Aliasing und Graustufenwerte normalisiert.
Die MNIST-Datenbank handschriftlicher Ziffern umfasst aktuell einen Trainingssatz von 50.000 Beispielen sowie einen Testsatz von 10.000 Beispielen, also eine Teilmenge des NIST-Datasets. Der MNIST-Datenfundus eignet sich damit gut, um Lerntechniken und Mustererkennungsmethoden mit nur minimalem Aufwand für Vorverarbeitung und Formatierung an reale Daten auszuprobieren.
Trainingsdaten
Wir laden also im Folgenden das MNIST-Dataset auf unsere Jupyter-Notebook-Instanz herunter, überprüfen die Daten, wandeln sie um und laden sie anschließend in unser S3-Bucket hoch. Das Umwandeln der Daten geschieht mit der numpy-Bibliothek für Python, indem wir das Format von numpy.array in durch Komma getrennte Werte (CSV) ändern.
Der zum Bewerten des Trainingsfortschritts verwendete XGBoost-Algorithmus erwartet eine Eingabe im CSV- oder LIBSVM- Format, wobei letztere eine Open-Source-Bibliothek für maschinelles Lernen ist.
Wir benutzen im Folgenden aber das einfacher anwendbare CSV-Format. Beginnen wir also mit dem Herunterladen des Datasets. AWS stellt dazu folgenden Beispielcode zur Verfügung.
%%time
import pickle, gzip, urllib.request, json
import numpy as np
# Load the dataset
urllib.request.urlretrieve("http://deeplearning.net/data/mnist/mnist.pkl.gz", "mnist.pkl.gz")
with gzip.open('mnist.pkl.gz', 'rb') as f:
train_set, valid_set, test_set = pickle.load(f, encoding='latin1')
print(train_set[0].shape) 
Der Code importiert u.a. zunächst die numpy-Bibliothek unter der Kurzbezeichnung „np“, eine typische Konvention unter Python-Programmierern. Dann lädt er das MNIST-Dataset (mnist.pkl.gz) als gepacktes Archiv von der MNIST-Datenbank-Website auf das Notebook herunter, entpackt die Datei und liest die Datasets „trains_set“, „valid_set“ und „test_set“ in den Arbeitsspeicher des Notebooks ein.
Das „train_set“ enthält Bilder mit handschriftlichen Zahlen zum Trainieren eines Modells. Das „valid_set“ verwendet die Bilder um mit Hilfe des o. e. XGBoost-Algorithmus den Trainingsfortschritt des Modells zu bewerten. Das „test_set“ wird später benutzt, um „Inferenzen“ zum Testen des bereitgestellten Modells abzurufen. In der Praxis würde man nun die Schulungsdaten analysieren, um festzustellen, welche Art Bereinigungen und Transformationen notwendig sind, um die Modell-Training noch zu verbessern.

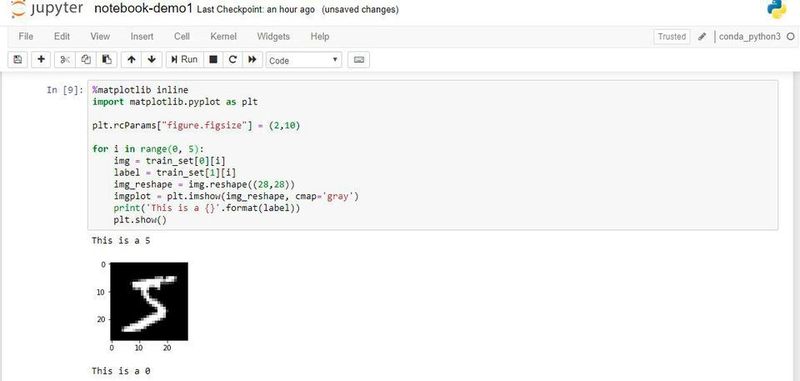
Das vorbereitete MNIST-Dataset muss allerdings nicht weiter bereinigt werden, da es für eben solche Zwecke entworfen wurde. Trotzdem könnten wir nun beispielsweise die ersten fünf Bilder des „train_set“ wie folgt anzeigen lassen, wozu wir z. B. in Python das Modul „pyplot“ aus der Bibliothek „matplotlib“ verwenden und „train_set“ aus den beiden Strukturen „train_set[0]“ für die eigentlichen Bilder und „train_set[1]“ für die Labels/ Bezeichnungen besteht.
Wie oben erwähnt, verwenden wir für das Transformieren des Trainings-Datasets und das Hochladen auf S3 den XGBoost-Algorithmus. Dieser erwartet für die Trainings-Eingabe Komma separierte Werte (CSV). Das Format der Trainings-Datasets ist numpy.array. Folgender Code wandelt das Dataset aus dem numpy.array-Format in ein CSV-Format um und lädt es auf das oben erzeugte S3-Bucket hoch.
%%time
import struct
import io
import csv
import boto3
def convert_data():
data_partitions = [('train', train_set), ('validation', valid_set), ('test', test_set)]
for data_partition_name, data_partition in data_partitions:
print('{}: {} {}'.format(data_partition_name, data_partition[0].shape, data_partition[1].shape))
labels = [t.tolist() for t in data_partition[1]]
features = [t.tolist() for t in data_partition[0]]
if data_partition_name != 'test':
examples = np.insert(features, 0, labels, axis=1)
else:
examples = features
#print(examples[50000,:])
np.savetxt('data.csv', examples, delimiter=',')
key = "{}/{}/examples".format(prefix,data_partition_name)
url = 's3n://{}/{}'.format(bucket, key)
boto3.Session().resource('s3').Bucket(bucket).Object(key).upload_file('data.csv')
print('Done writing to {}'.format(url))
convert_data() 
Bei Erfolg sollte der Ausgabe zu entnehmen sein, dass 50.000 Trainings-Datensätze, 10.000 Validierungs-Datensätze und 10.000 Test-Datensätze mit einer Größe von jeweils 784 (28x28 Pixel) oder „Neuronen“ (das neuromale Netz interpretiert die 784 Helligkeitswerte des Bildes als „Eingänge“ für den Input-Layer) erfolgreich auf das angegebene S3-Bucket hochgeladen wurden.
Trainieren eines Modells
Für das Trainieren, Bereitstellen und Validieren eines Modells in Amazon SageMaker können Nutzer wahlweise das Amazon SageMaker-Python-SDK oder das AWS SDK für Python (Boto3) benutzen. Optional klappt das natürlich auch direkt an der Python-Konsole, wir verwenden aber der Einfachheit halber wieder eine Notebook-Instance und eines der genannten SDKs.
Für den Anfang ist das Verwenden des SageMaker-Python-SDK von Amazon besser verständlich, da es eine Reihe von Implementierungsdetails abstrahiert und einfacher zu verwenden ist. Ob ein neuronales Netz überhaupt in der Lage ist, Vorhersagen zu machen und von welcher Güte diese sind, hängt von Trainieren des Modells mit geeigneten Trainingsdaten und Machine-Learning-Algorithmus ab.
Jeder ML-Algorithmus erstellt anhand von Beispieldaten eine allgemeine Lösung, die auch als „Modell“ bezeichnet wird. Diese muss möglichst gut zur zu beantwortenden Frage passen. Hat der Entwickler mithilfe von Beispieldaten ein Modell entwickelt, kann er dieses benutzen, um die gleiche Frage mit einem anderen (quasi „neuen“) Satz von Daten zu beantworten. Dieser Vorgang wird auch als Abrufen von Inferenzen (Schlussfolgern) bezeichnet.
Amazon SageMaker bringt bereits zahlreiche MachineLearning-Algorithmen, die man allgemeine für eine große Zahl von typischen Problemarten benutzen kann, wie z. B. Bildklassifikation, DeepAR-Prognosen, Factorization Machines, semantische Segmentierung oder den erwähnten XGBoost-Algorithmus
Allgemein lässt sich aber sagen, dass man das mittels eines Modells zu lösende Problem gut verstehen muss, denn das „Format“ Antwort wirkt sich auf den verwendeten Algorithmus aus. Möchte man etwa eine Mailing-Kampagne zur Gewinnung neuer Kunden mit Hilfe eines neuronalen Netzes steuern, muss man sich überlegen, welche Art von Antwort man anstrebt.
Denkbar sind z. B. Antworten, die in eine diskrete Kategorie passen wie „Hat der Kunde schon früher auf Marketing-Kampagnen geantwortet“ oder „Zu welchen Kundensegment gehört der Kunde“. Ein Algorithmus der sich gut für die diskrete Klassifikation eignet wäre dann entweder der erwähne XGBoost-Algorithmus oder der Algorithmus für lineares Lernen.
Im ersten Fall würde man z. B. für den XGBoost-Algorithmus den „objective“-Parameter auf „logistic“ setzen. Es sind aber auch quantitative Antworten denkbar wie „Was ist der zu erwartende ROI dieses Kunden in Bezug auf den ROI aus dem letzten Mailing. Hierzu könnte man ebenfalls den XGBoost-Algorithmus, allerdings mit dem objective-Parameter „linear“ verwenden.
:quality(80)/images.vogel.de/vogelonline/bdb/1639700/1639746/original.jpg "In Jupyter-Notebooks darf man nicht vergessen, die nebenstehende Zelle anschließend auch auszuführen (Run). (Drilling / AWS)")
Machine Learning mit Python: Einführung in SageMaker und Jupyter
Im nächsten Teil dieses Workshops befassen wir uns konkret mit dem Trainieren, Bereitstellen und Validieren eines Modells mit Hilfe von Amazon SageMaker.
Dieser Beitrag stammt von unserem Partnerportal Dev-Insider.de.
:quality(80)/images.vogel.de/vogelonline/bdb/1637000/1637041/original.jpg "DNP/AISS1 Embedded-Machine-Learning-Starterkit: Das Kit besteht aus einem kompakten Evaluierungsboard mit einem 32-Bit-ARMCortex-A5-Rechnermodul, einer 10/100Mbps-LAN-Schnittstelle sowie verschiedenen Sensoren (1x triaxialer Inertialsensor, 1x Umgebungssensor mit Temperatur, Luftdruck und Luftfeuchtigkeit, 1x Kompasssensorelement). (SSV Software Systems GmbH)")
Embedded Machine Learning: ML-Algorithmus statt klassischer Firmware
:quality(80)/images.vogel.de/vogelonline/bdb/1644300/1644370/original.jpg "Mehr als 1200 Teilnehmer treffen sich jährlich im Dezember in Sindelfingen, um sich über die Entwicklungen im Embedded Software Engineering fortzubilden und auszutauschen. (foto art Elisabeth Wiesner)")
Embedded Software Trends 2019: C++, Python, Machine Learning und vieles mehr
:quality(80)/images.vogel.de/vogelonline/bdb/1608500/1608530/original.jpg "Die Integration der neuen PyTorch-Bibliotheken erfordert ein etwas anderes Vorgehen. (PyTorch)")
Open-Source-Bibliothek PyTorch 1.2 verfügbar
(ID:46244882)
:quality(80)/p7i.vogel.de/wcms/56/a3/56a3c9077b8dfe8fbb34d3ecc1284cc1/0127608937v2.jpeg "Das Phoenix Bootcamp zeigt, wie aus Daten Bedeutung und Handlung entsteht – mit Wissensgraphen, praktischen Übungen und einem realen Use Case aus dem Rennsport. (Bild: Schmid Elektronik)")
:quality(80)/p7i.vogel.de/wcms/eb/23/eb23785d23e0a13df6f6344f6d880bd0/0129487941v1.jpeg "Illustration eines \"In-the-Loop\" Testansatzes: Struktur eines Reglers (links) und Realisierung eines Reglers auf einem Steuergerät (rechts). (Bild: embeff)")