:quality(80)/p7i.vogel.de/wcms/b5/ae/b5ae6808f29fc09bf61b47807604bcf4/0131740517v2.jpeg "Wenn KI Aktuatoren steuert, wird Edge AI zur Physical AI. Hinsichtlich der Software-Entwicklung kommt es dabei nicht nur auf die Modelleistung an: gerade Safety, Compliance und eine zertifizierte Toolchain werden hier zu entscheidenden Faktoren. (Bild: @homaappliances/Unsplash)")
:quality(80)/p7i.vogel.de/wcms/b8/20/b8203d9f2b6f6e61bff6c3fda15042d3/0128235802v2.jpeg "Die Forschenden aus dem Lehrstuhl für Robotik, Künstliche Intelligenz und Echtzeitsysteme testen die neue Architektur am Teststand der TUM. Im Bild (von links nach rechts): Chengdong Wu, Nils Purschke und Sven Kirchner. (Bild: besser 3 / TU München)")
:quality(80)/p7i.vogel.de/wcms/79/90/79901d8c1934b11223a53cb900b1aa85/das-20building-2092-20bei-20der-20microsoft-zentrale-20in-20redmond-20--20quelle-20coolcaesar-20via-20wikimedia-20commons-5184x2915v1.jpeg "Das Building 92 bei der Microsoft-Zentrale in Redmond. (Wikimedia Commons)")
:quality(80)/p7i.vogel.de/wcms/31/92/3192d2bddbdb052afd8904128dd7aec1/0123884994v2.jpeg "Projekte zur Entwicklung von Embedded-Systemen, wie auch die Systeme selbst, werden zunehmend komplexer. Modellbasiertes System-Engineering (MBSE) soll dabei helfen, diese zunehmende Komplexität in den Griff zu bekommen. Doch wann stößt das Prinzip an seine Grenzen? (Bild: KI-generiert / DALL-E)")
:quality(80)/p7i.vogel.de/wcms/da/34/da343cfac1c945d425a8c650abd7c448/0131414071v2.jpeg "Softwaredefinierte Systeme müssen auch dann zuverlässig zusammenarbeiten, wenn Netzwerke schwanken oder ausfallen. RTI Connext und der Persistence Service können dafür sorgen, konsistente Datenflüsse zu gewährleisten. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/ba/d7/bad734452b1b8360591396b49da37b72/0130644400v1.jpeg "Die Begriffe Echtzeit und Virtualisierung erscheinen zunächst widersprüchlich, da sie auch aus den konträren Domänen OT (Operational Technology) und IT (Information Technology) stammen. Virtualisierung bedeutet aber im Wesentlichen die Entkopplung einer bestimmten Applikation von der zugrunde liegenden Hardware, was keinen direkten Kontrast zu Echtzeit bedeuten muss. Dieser Artikel erläutert die verschiedenen technischen Möglichkeiten, eine Applikation von der Hardware zu entkoppeln, um anschließend deren individuelle Tauglichkeit zum Ablauf echtzeitkritischer Systeme zu evaluieren. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/cc/53/cc53ebfd9f45b28eb918a8098b63846b/0127825678v1.jpeg "Im zweiten und letzten Teil der Artikelserie zu Latenzen wird gezeigt, wie sich Latenz mit dem richtigen RTOS, Interrupt-Optimierung, Low-Level-Code und Co-Design gezielt senken lässt. (Bild: Green Hills Software)")
:quality(80)/p7i.vogel.de/wcms/ac/ea/acea3ca6c15e0bd261c8bde5d3fe7bfb/0127825678v2.jpeg "Bild 1: Um Latenzzeiten in echtzeitkritischen Systemen verringern zu können braucht es erst einmal Verständnis, wie diese entstehen. Im ersten Teil unserer zweiteiligen Reihe werden die Schlüsselfaktoren untersucht, die sowohl auf Hardware- als auch auf Software-Ebene zur Latenz beitragen. (Bild: Green Hills Software)")
:quality(80)/p7i.vogel.de/wcms/56/9b/569b4da4d1f2e4ce6f41918f86d00c04/0131738385v2.jpeg "Laut der Atlassian-Studie „State of Teams 2026“ verlieren Fortune-500-Unternehmen jedes Jahr schätzungsweise 161 Milliarden US-Dollar durch KI-bedingte Reibungsverluste. Das Problem ist mangelnde Koordination: 80 Prozent der Arbeit in Unternehmen findet innerhalb von Teams oder teamübergreifend statt, aber nur 24 Prozent der Führungskräfte legen ihre KI-Initiativen gezielt auf diese Zusammenarbeit aus. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/d9/c1/d9c121f0680f16e547502038f5c26481/0130027942v2.jpeg "Laut dem aktuellen State of Automotive Software Development Report von Perforce verwenden bereits 71 % der befragten Unternehmen KI in der Entwicklung von Fahrzeugsoftware. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/75/3d/753d0fa44b344d363e25c91dc0752635/0129134302v2.jpeg "Volle Säle, reger Austausch: Trotz einer spürbaren Konjunkturflaute gerade im Automotive-Bereich fanden sich erneut um die 1000 Teilnehmer in der Stadthalle Sindelfingen zum ESE Kongress 2025 ein. (Bild: Nicolas Det)")
:quality(80)/p7i.vogel.de/wcms/bb/6e/bb6e94900bbd812e9aeb6c9bda0188f2/0131853806v2.jpeg "KI-generierter Code und wachsende Codebasen überfordern klassische AppSec-Audits. Kontinuierliche, in den Entwicklungszyklus eingebettete Sicherheitsprüfungen ersetzen das veraltete Modell. (Bild: © Nattanon - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/b4/2d/b42d8991fc58ac24aeb6e87d415345a9/0132049161v2.jpeg "Die Linux Foundation und führende Unternehmen der Software-Branche haben die Initiative „Akrites“ ins Leben gerufen. Ihr Ziel: Kritische Open-Source-Software vor KI-gestützten Cyberbedrohungen zu schützen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/29/df/29dfe92c81f1d3608224694316b2179b/0131967433v1.jpeg "„Patch the Planet“: Die von OpenAI gestartete Initiative soll mittels KI-gestützter Sicherheitsanalyse Open-Source-Maintainer entlasten, indem potenzielle Schwachstellen vor der Weitergabe an Projekte von Experten geprüft und in belastbare Patches überführt werden. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/e3/f3/e3f3e7bf05f03eb91d7c4d3d0c388b96/0131831391v2.jpeg "Während Desktop-Systeme heute standardmäßig mit Exploit-Mitigation-Mechanismen abgesichert sind, fehlen vergleichbare Schutzmaßnahmen in vielen Embedded Devices noch immer. Das macht vernetzte Geräte im Feld zu einem attraktiven Angriffsziel und verschärft den Handlungsdruck für Hersteller. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/e4/59/e45954efb72f640648a8bf8cac1259dc/0132012442v1.jpeg "Das Rust Commercial Network soll Unternehmen, professionelle Anwender und das Rust-Projekt enger vernetzen und den Austausch über den produktiven Einsatz der Sprache fördern. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/41/c9/41c91ed48343a6014ddcd2aaa9029248/0130954766v2.jpeg "In welcher Programmiersprache wird Fahrzeug-Software geschrieben? Diese Frage rückt nunmehr in Bereiche, in denen über Architektur, Risiko und Zulassung entschieden wird. (Bild: frei lizensiert bei Pexels)")
:quality(80)/p7i.vogel.de/wcms/38/41/384121ebf647b1fc2149044fe5857c51/0131567723v2.jpeg "Microsoft plant, bis zum Release von C# 16 die Speichersicherheit der Programmiersprache grundlegend zu verbessert. Dabei orientiert sich das Entwicklerteam an Paradigmen, die aus Rust bekannt sind. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/47/f5/47f5a305c48bfcaf3daae7e6b7478a0f/0131065910v2.jpeg "Rust hält Einzug in die Fahrzeugsoftware und adressiert vor allem Speicher- und Sicherheitsrisiken in vernetzten Steuergeräten. Für OEMs und Zulieferer stellt sich damit weniger die Frage „Rust oder C“, sondern welche Komponenten zuerst von einem Wechsel profitieren. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/36/14/36149e1b05c9f269b5ea6cdb4bd732e6/0131957621v2.jpeg "Im Vergleich zum April-Release weist das jüngste Wartungs-Update von Rasperry Pi OS nur einoge Ergänzungen und Fehlerkorrekturen auf. Am Bedeutendsten sind der Umstieg auf den Linux-LTS-Kernel 6.18.3 sowie einer bessere, einheitlichere Unterstürtzung für Touchscreens. (Bild: Raspberry PI)")
:quality(80)/p7i.vogel.de/wcms/0d/9b/0d9be5033416dffb1b4f5cc050560a25/0131796023v2.jpeg "Vom Gateway zur Central Unit: Im SDV werden Fahrzeugfunktionen zentralisiert und müssen über klare Partitionierung, Isolation und Safety-Scope abgesichert werden. (Bild: Elektrobit)")
:quality(80)/p7i.vogel.de/wcms/2e/89/2e8965af7611ed0c0db93bdb9f973cbb/0131759111v1.jpeg "Fractal basiert auf einem neuen Konzept: dem „Outer Kernel“-Thread, der sich im Speicher eines Benutzerprozesses befindet, aber mit Kernel-Rechten ausgeführt wird. Entwicklerund MIT-Doktorand Joseph Ravichandran bezeichnet das resultierende Betriebssystem als das „Elektronenmikroskop der Betriebssysteme“. (Bild: MIT / Gabriel Maragaño)")
:quality(80)/p7i.vogel.de/wcms/bd/15/bd15e3adf9e8d2e15c1485d809078729/0131621839v2.jpeg "Sicherheitsforscher melden manipulierte Red-Hat-Pakete im npm-Registry. Betroffene Systeme, welche die befallenen Pakete heruntergeladen haben, gelten als direkt kompromittiert, weil der Schadcode schon bei der Installation ausgeführt wird. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d8/b1/d8b155da6f9b74886c34845a83ce451d/0131897755v1.jpeg "Das Marketingversprechen verspricht eine reibungslose Code-Übersetzung. In der Praxis bricht die automatisierte Migration komplexer Legacy-Systeme laut Gartner an ihren eigenen Grenzen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d2/e9/d2e9736dbd5b904cb34192c7b350e1d5/0131669814v2.jpeg "Unter dem Druck des Managements wiegt die schnelle Veröffentlichung von Software oft mehr als ihre Qualität. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/8a/09/8a094e681c2f4b9aefbeb7bd2732af4a/0131173224v1.jpeg "Unit-Tests in regulierten Branchen müssen mehr leisten als reine Fehlerprüfung. Der Artikel zeigt, wie GoogleTest bewertet wird und welche Rolle C/C++test CT dabei spielen kann. (Bild: Parasoft)")
:quality(80)/p7i.vogel.de/wcms/2e/b2/2eb2a82d215c72f59c1fde532c092e87/0131010297v2.jpeg "MRT-Bilderkennungssystem: Gerade in der Medizintechnikkann der Einsatz von KI in einem Embedded Sytsem massive Vorzüge Bbringen. Umso mehr kommt es dabei aber auch auf die Zuverlässigkeit der Tests an, um Safety-Standards einzuhalten. (Bild: Magnific / Yaroslav Astakhov)")
:quality(80)/p7i.vogel.de/wcms/67/b2/67b245336515275479705d500b1bc74f/0132006001v2.jpeg "Produktivitätsparadoxon: KI beschleunigt die Codeerstellung, doch Kontrolle, Nachverfolgbarkeit und Governance werden laut Gitlab's AI Accountability Report zum neuen Engpass im Software-Lieferprozess. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/9f/9d/9f9d8357928662c1173bad86e63f0fb0/0126749087v2.jpeg "Miss Magic: Für das aktuelle vom KITCar-Team für die Cognitive Autonomous Driving Challenge entwickelte selbstfahrende Modellfahrzeug musste das zugrunde liegende Embedded-System komplett umgestellt werden. Zum Einsatz kamen die Open-Source-Systeme FreeRTOS und micro-ROS. Dabei musste das mit Multithreading unerfahrene Team umfassende Analysem am System durchführen. (Bild: KIT)")
:quality(80)/p7i.vogel.de/wcms/27/b9/27b9cfbb678630047f85e1adc55f7df7/0114455762.jpeg "Bild 1. Unterschiedliche Verarbeitungszeiten und Garantien für eine bestimmte Echtzeit-Task (Bild: LDRA)")
:quality(80)/p7i.vogel.de/wcms/4d/96/4d9621a180cfee96ba85d2da83163461/0105948132.jpeg "Eine effektive Verwaltung und nahtlose Orchestrierung verschiedener Softwarekomponenten auf einem einzigen SoC kann auf vielfältige Weise erreicht werden. (Bild: Siemens Software )")
:quality(80)/p7i.vogel.de/wcms/34/05/3405327567eb345e9c0c326a590cd9ae/0105886699.jpeg "Mithilfe der UDE 2022 können Entwickler alle Funktionseinheiten aus einer Umgebung heraus ansprechen. Kerne lassen sich gemeinsam, in Gruppen oder einzeln debuggen. (Bild: PLS)")
:quality(80)/p7i.vogel.de/wcms/22/89/22896600c7f19a5813fa824ee8207dd4/0122524970v2.jpeg "Ein halbautomatischer Webstuhl des französischen Erfinders Basile Bouchon aus dem Jahr 1725, zu sehen im Musée des arts et métiers, Paris. Die Löcher im Papierband gaben vor, welche Nadelöhre gehoben wurden, durch die das Muster der nächsten Reihe im Webstuhl zu laufen hatte. Je nach gewünschten Muster konnten die Lochbänder ausgewechselt werden - das Prinzip programmierbarer Maschinen war geboren. (Bild: Basile Bouchon 1725 loom / Dogcow / CC BY-SA 3.0)")
:quality(80)/p7i.vogel.de/wcms/e7/cf/e7cf5a22f39eddc3235f047c566b747e/0122159010v1.jpeg "Abstraktionsschichten (Symbolbild) (Bild: KI-generiert / DALL-E)")
:quality(80)/p7i.vogel.de/wcms/43/c4/43c4067994de48347a260c6191e88528/0103046501v1.jpeg "(Logo: Rust Foundation)")
:quality(80)/p7i.vogel.de/wcms/74/a1/74a1fcd5d60af69422390e97fbf77dcd/0109296819.jpeg "Das war der ESE Kongress 2022. (Bild: Elisabeth Wiesner)")
Der Approximationsalgorithmus
Für verschiedene Probleme lassen sich nur durch Annäherung bzw. Approximation optimale Lösungen finden. Durch einen geeigneten Approximationsalgorithmus versuchen Informatiker, sich dem optimalen Ergebnis anzunähern, so etwa in der Graphentheorie, die Beziehungen in Netzwerken darstellt.
Anbieter zum Thema
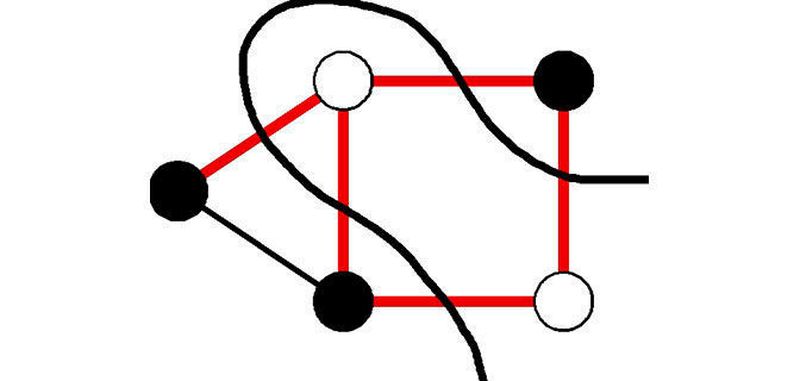
In der Informatik und der Betriebswirtschaftslehre sind Approximationsalgorithmen effiziente Berechnungsmethoden, um angenäherte Lösungen für NP-harteOptimierungsprobleme zu finden. Diese Lösungen müssen beweisbare Garantien hinsichtlich der Entfernung der gelieferten Lösung von der optimalen vorlegen.
„Im Banking werden Approximationsalgorithmen für das Kredit-Scoring genutzt“, sagt Benjamin Aunkofer, Chief Data Scientist bei Datanomiq. „Als Anwendungsfall ist Kredit-Scoring zwar alt, kann aber eine stetige Verbesserung mit Machine Learning vorweisen.“ Aunkofer zählt weitere Use Cases auf, so etwa im Versicherungswesen: „Da geht es um Schadensprognosen.“
:quality(80)/images.vogel.de/vogelonline/bdb/1609900/1609902/original.jpg "(Thore Husfeldt / CC BY-SA)")
:quality(80)/images.vogel.de/vogelonline/bdb/1609900/1609903/original.jpg "(Cliquenproblem / MichaelGl / CC BY-SA 3.0)")
:quality(80)/images.vogel.de/vogelonline/bdb/1609900/1609904/original.jpg "(MichaelGl / CC BY-SA 3.0)")
:quality(80)/images.vogel.de/vogelonline/bdb/1609900/1609905/original.jpg "(MichaelGl / CC BY-SA 3.0)")
In der Industrie tauchen Approximationsalgorithmen in der prädiktiven Wartung alias Predictive Maintenance auf. „Hier geht es um die Beobachtung der Abnutzung und die anschließende Vorhersage der idealen Wartungsintervalle.“ Eine optimale Wartung kann über Menschenleben entscheiden.
Im Handel werden sehr große Summen umgesetzt, aber nur minimale Margen erzielt. Daher lohnt sich jeder Prozentpunkt hinterm Komma, um die Marge zu vergrößern. „Approximationsalgorithmen lassen sich hier zur Vorhersage der Nachfrage und der Retouren nutzen, also von der Produkt-Ebene über die Shop-Ebene bis hin zur Kunden-Ebene. Sie geben die Retouren-Wahrscheinlichkeit für jede einzelne Kundenbestellung an. Es lassen sich also Verlustrisiken ebenso berechnen wie die Kundenbevorzugung – etwa in einem Bonusprogramm – steuern.
Erstaunliche Theorien
In der theoretischen Informatik ergeben sich Approximationsalgorithmen aus der weithin akzeptierten Vermutung, dass P ungleich NP. Aufgrund dieser Vermutung lässt sich eine große Klasse von Optimierungsprobleme nicht in polynomieller Zeit lösen. Approximationsalgorithmen versuchen daher, sich optimalen Lösungen für solche Probleme in polynomieller Zeit zu nähern.
In der großen Mehrheit aller Fälle wird die o. a. Garantie durch Multiplikationsalgorithmen ausgedrückt: als Annäherungsrate oder -faktor. Das heißt, die die optimale Lösung liegt innerhalb eines (festgelegten) Multiplikationsfaktors der gelieferten Lösung. Auch die Addition lässt sich für diesen Zweck heranziehen.
Ein erwähnenswertes Beispiel für einen Approximationsalgorithmus, der beide Methoden mit Lösungen nutzt, ist der klassische Approximationsalgorithmus von Lenstra, Shmoys und Tardos namens „Scheduling on Unrelated Parallel Machines“. Dabei werden Maschinen, Aufgaben und Kosten miteinander korreliert. Man sieht: Es gibt handfeste Anwendungsgebiete für diese scheinbar so abstrakte Methode, wie die auch die oben genannten Anwendungsfälle illustrieren.
Weitere Optimierungsprobleme
In der theoretischen Informatik gibt es mehrere Optimierungsprobleme. So wird etwa nach einem Algorithmus gesucht, der hinsichtlich des Metric-Traveling-Salesman-Problems (TSP) den „1,5-Approximationsalgorithmus“ von Christofides übertrifft. Siehe dazu den ersten Teil über das TSP-Problem. Das TSP-Problem spielt überall in der Logistik eine bedeutende Rolle. Ein weiteres Beispiel ist der Algorithmus für „Maximalen Schnitt“. Dieser Algorithmus löst ein theoretisches Graphen-Problem mithilfe von hochdimensionaler Geometrie (siehe Anblaufbild).
Ein einfaches Beispiel für einen Approximationsalgorithmus ist die Lösung für das Minimum-Vertex-Cover-Problem, wobei Vertex ein Begriff aus der Graphentheorie sein kann, der einen Knoten bezeichnet. Dabei gibt es erstaunlicherweise einen konstant großen Faktor für den Approximationsalgorithmus, nämlich genau 2. Berücksichtigt man die Vermutung für einzigartige Spiele (Unique Games Conjecture), dann ist dieser Faktor sogar der bestmögliche. Die Graphentheorie wird auf alle Arten von vernetzten Beziehungen angewandt, so etwa in sozialen Netzwerken wie Facebook.
Güte von Approximationsalgorithmen
Um die Optimierung beurteilen und verwalten zu können, muss der Nutzer herausfinden, was sein Approximationsalgorithmus überhaupt taugt. Das herauszufinden, ist kein Hexenwerk. Man muss nur ein paar Faktoren und Variablen formulieren und in den Algorithmus einsetzen.
Es sei S ( I ) die zu einer Eingabe I gehörige Menge zulässiger Lösungen. Zu jeder möglichen Lösung y ∈ S ( I )\ in S(I) sei v ( y ) der Wert der Zielfunktion für y. Der Zielfunktionswert einer optimalen Lösung für Eingabe I sei v *. Ein Approximationsalgorithmus (oder Approximationsverfahren) gibt bei Eingabe I eine Lösung y ∈ S aus, sodass (v ( y ) relativ nah an v * liegt.
Ist die von einem Approximationsverfahren für die Eingabe berechnete Lösung, so ist die Güte des Approximationsverfahrens bei der Eingabe
- bei Maximierungsaufgaben als r l = v * v ( y ) frac {v^{*}}{v(y)}}} und bei
- Minimierungsaufgaben als r l = v ( y ) v * frac {v(y)}{v^{*}}}} definiert.
Es ist also immer r l ≥ 1. Gilt r l = 1, liefert der Algorithmus eine optimale Lösung für I .
Hat ein Approximationsverfahren für alle möglichen Eingaben I eine Güte von r l höchstens α, so spricht man von einer α-Approximation.
Klassen von Approximationsalgorithmen
Optimierungsprobleme werden in der Theoretischen Informatik in verschiedene Approximationsklassen unterschieden, je nachdem welcher Grad an Approximation möglich ist:
1. APX
Die Abkürzung APX steht für „approximable“ und deutet an, dass das Optimierungsproblem, zumindest bis zu einem gewissen Grad, effizient approximierbar ist. Ein Problem liegt innerhalb der Klasse APX, wenn eine Zahl r und ein polynomieller Algorithmus, der bei jeder zulässigen Eingabe I eine Lösung mit einer Güte ≤ r liefert, existieren.
2. PTAS/PAS
PTAS oder PAS steht für „polynomial time approximation scheme“. Anders als bei der Klasse APX wird hier für jedes δ ∈ ( 0 , 1) gefordert, dass ein polynomieller Algorithmus existiert, der bei jeder zulässigen Eingabe eine Lösung mit einer Güte r ≤ 1 + δ liefert. Der Algorithmus muss also nicht nur für eine bestimmte Güte, sondern für jede Approximationsgüte (s. o.) effizient sein.
3. FPTAS
FPTAS steht für „fully polynomial time approximation scheme“. Hier wird gefordert, dass sich der Algorithmus nicht nur polynomiell zur Eingabe, sondern auch zur Güte der Approximation verhält; Dass er also zu jeder Eingabe I und jedem k ∈ N eine Lösung mit der Güte r ≤ 1 + 1 / k ausgibt und seine Laufzeit polynomiell in x und k ist.
Es gilt: P O ⊆ F P T A S ⊆ P T A S ⊆ A P X ⊆ N P O .
Unter der Annahme P ≠ N P sind die obigen Inklusionsabbildungen echte Inklusionen. Das heißt, es gibt zum Beispiel mindestens ein Optimierungsproblem, das in der Klasse PTAS liegt, aber nicht in der Klasse FPTAS. Unter dieser Annahme existiert auch mindestens ein Optimierungsproblem, das nicht in APX liegt.
FPTAS-Beispiel: das Cliquenproblem
Das oben Gesagte lässt sich unter der Annahme P ⊊ N P zum Beispiel für das Cliquenproblem zeigen. Dieses Entscheidungsproblem der Graphentheorie liefert seit rund fünfzig Jahren zahlreiche interessante Lösungen.
Eine Clique bezeichnet in der Graphentheorie eine Teilmenge von Knoten in einem ungerichteten Graphen, bei der jedes Knotenpaar durch eine Kante verbunden ist. Zu entscheiden, ob ein Graph eine Clique einer bestimmten Mindestgröße enthält, wird „Cliquenproblem“ genannt und gilt, wie das Finden von größten Cliquen, als algorithmisch schwierig.
Es ist gefragt, ob es zu einem einfachen Graphen G und einer Zahl n eine Clique der Mindestgröße n in G gibt; das heißt, ob G zumindest n Knoten hat, die alle untereinander paarweise verbunden sind. Das Optimierungsproblem fragt nach der Cliquenzahl eines Graphen: Wie viele kann er enthalten?
Das zugehörige Suchproblem fragt nach einer größten Clique. Eine größte Clique lässt sich unter bestimmten Bedingungen in polynomieller Zeit berechnen, dauert also nicht ewig. Die Berechnung einer maximalen Clique gelingt bereits mit einem einfachen Greedy-Algorithmus. Dieser wird Gegenstand eines weiteren Grundlagenartikels sein.
„BI-Systeme sind noch weitgehend frei von Approximationsalgorithmen“, befindet Benjamin Aunkofer. „BI-Systeme bestehen heute noch im Wesentlichen aus Data Warehousing (= saubere Datenbereitstellung) und Dashboarding (= Nutzung dieser Daten via Standard Reporting). Zukünftig werden BI-Systeme aber vermehrt Predictive Analytics aufnehmen.“
:quality(80)/images.vogel.de/vogelonline/bdb/1602200/1602206/original.jpg "Kernidee von LOF ist, die lokale Dichte eines Punktes mit der seiner Nachbarn zu vergleichen- (gemeinfrei)")
So deckt der Local Outlier Factor Anomalien auf
:quality(80)/images.vogel.de/vogelonline/bdb/1592200/1592281/original.jpg "Kernel-Maschinen werden verwendet, um nichtlinear trennbare Funktionen zu berechnen, um so eine linear trennbare Funktion höherer Ordnung zu erhalten. (Kernel Machine.svg / Alisneaky, svg version by User:Zirguezi / CC BY-SA 4.0)")
Optimale Clusteranalyse und Segmentierung mit dem k-Means-Algorithmus
:quality(80)/images.vogel.de/vogelonline/bdb/1580900/1580976/original.jpg "Prinzipbild des Rete-Algorithmus. Deutlich sind zwei Netzwerke (Alpha, Beta) zu erkennen und dass darin jeweils sehr viel Speicher benötigt wird. Dieser hohe Speicherbedarf ist einer der wenigen Nachteile des Rete-Algorithmus. (gemeinfrei)")
Der Rete-Algorithmus: Speed für Mustererkennung
Dieser Beitrag stammt von unserem Partnerportal Bigdata-Insider.de.
(ID:46112104)
:quality(80)/p7i.vogel.de/wcms/56/a3/56a3c9077b8dfe8fbb34d3ecc1284cc1/0127608937v2.jpeg "Das Phoenix Bootcamp zeigt, wie aus Daten Bedeutung und Handlung entsteht – mit Wissensgraphen, praktischen Übungen und einem realen Use Case aus dem Rennsport. (Bild: Schmid Elektronik)")
:quality(80)/p7i.vogel.de/wcms/8a/09/8a094e681c2f4b9aefbeb7bd2732af4a/0131173224v1.jpeg "Unit-Tests in regulierten Branchen müssen mehr leisten als reine Fehlerprüfung. Der Artikel zeigt, wie GoogleTest bewertet wird und welche Rolle C/C++test CT dabei spielen kann. (Bild: Parasoft)")